안녕하세요~ 솔루디오입니다^^
요즘 ChatGPT나 여러 AI 툴을 쓰다 보면 문득 소름 돋을 때가 있지 않나요? "와, 진짜 사람처럼 생각하는 것 같은데?"
하지만 겁먹을 필요 없습니다. 알고 보면 AI도 외계인이 만든 게 아니라, 철저하게 짜인 **'순서'와 '규칙'**에 따라 움직이는 프로그램이거든요. 요리 레시피부터 넷플릭스 추천까지, 우리 일상 속 예시로 AI의 뇌 구조를 들여다볼까요?
이전 글을 읽고 오시면 더 이해하기 좋아요^^
- [AI 개념 정리 2] AI는 어떻게 공부할까? 넷플릭스와 알파고로 배우는 머신러닝 원리
- [AI 개념 정리 1] AI 종류 완벽 정리: 약한 AI와 강한 AI 차이점은? (feat. ChatGPT)
지난 이야기: 머신러닝의 '방법'
이전 글에서 우리는 머신러닝의 세 가지 학습 방식을 배웠습니다. 지도학습은 선생님과 함께 공부하는 것처럼, 비지도학습은 스스로 탐험하는 것처럼, 강화학습은 시행착오로 배우는 것처럼 작동한다고 했죠.
그런데 문득 이런 생각이 들지 않나요?
"그래서 AI는 정확히 '어떻게' 학습하는 거지?"
요리를 배우는 방법은 알았는데, 실제 레시피가 뭔지 모르는 것과 같습니다. 운전면허 시험에 합격하는 방법은 알았는데, 실제로 운전하는 법은 아직 배우지 않은 거죠.
오늘은 바로 그 '방법', 즉 알고리즘에 대해 알아보겠습니다.
"알고리즘"이라는 단어가 어렵게 느껴지시나요? 걱정 마세요. 우리는 이미 매일 알고리즘을 사용하고 있습니다. 아침에 일어나서 출근하는 과정, 커피를 내리는 과정, 심지어 이 글을 읽는 과정도 모두 알고리즘이에요.
알고리즘이란 무엇인가?
가장 쉬운 정의
알고리즘은 문제를 해결하기 위한 단계적인 절차입니다.
한 문장으로 줄이면 이렇습니다: "순서가 있는 방법"
너무 간단한가요? 맞습니다. 그래서 좋은 거예요!

우리 주변의 알고리즘
알고리즘은 컴퓨터만의 것이 아닙니다. 우리 일상 곳곳에 있죠.
요리 레시피가 대표적인 알고리즘입니다:
- 재료를 준비한다
- 야채를 씻어서 자른다
- 팬에 기름을 두른다
- 야채를 볶는다
- 양념을 넣는다
- 완성!
각 단계가 순서대로 진행되고, 이 순서를 따르면 원하는 결과(맛있는 요리)가 나옵니다.
아침 루틴도 알고리즘입니다:
- 알람이 울린다
- 침대에서 일어난다
- 샤워를 한다
- 옷을 입는다
- 아침을 먹는다
- 출근한다
만약 순서를 바꾸면 어떻게 될까요? 3번과 4번을 바꿔서 옷을 입고 나서 샤워하면... 문제가 생기죠!
알고리즘의 3요소
모든 알고리즘은 세 가지로 구성됩니다:
입력 (Input) → 처리 (Process) → 출력 (Output)
예를 들어볼까요?
길 찾기 알고리즘:
- 입력: 출발지, 목적지
- 처리: 여러 경로 중 가장 빠른 길 계산
- 출력: 추천 경로
스팸 필터 알고리즘:
- 입력: 이메일 내용
- 처리: 스팸 패턴 확인
- 출력: 정상 메일 or 스팸 메일
전통적 알고리즘 vs AI 알고리즘
그렇다면 AI 알고리즘은 뭐가 다를까요?
전통적 알고리즘:
- 사람이 모든 규칙을 미리 정해줌
- 예: "Subject에 '무료'가 있고 'http://'가 5개 이상이면 스팸"
- 정해진 규칙대로만 작동
AI 알고리즘:
- 데이터를 보고 스스로 규칙을 학습
- 예: 1만 개의 스팸 메일을 보고 공통 패턴 발견
- 새로운 상황에도 적용 가능
이게 AI의 핵심입니다. 데이터로부터 배운다는 것!
전통적 프로그래밍이 "레시피북을 따라하는 것"이라면, AI는 "여러 요리를 먹어보고 자기만의 레시피를 만드는 것"이에요.
패턴 인식의 원리
패턴이란 무엇인가?
패턴은 반복되는 규칙입니다.
생각해보세요. 우리는 어떻게 "내일 비가 올 것 같다"고 예측할까요?
"하늘에 먹구름이 많고, 습도가 높고, 바람이 강하면 → 비가 올 확률이 높다"
이게 패턴입니다. 과거 경험에서 발견한 규칙이죠.

AI는 어떻게 패턴을 찾을까?
의사가 환자를 진단하는 과정을 생각해보세요:
환자: "열이 나고 기침이 나요." 의사: "목도 아프신가요?" 환자: "네, 아파요." 의사: "감기 같은데요. 약 처방해드릴게요."
의사는 수많은 환자를 진료하며 패턴을 배웠습니다:
- 열 + 기침 + 목 통증 = 감기 가능성 높음
- 열 + 두통 + 구토 = 독감 가능성 높음
- 열 + 발진 = 다른 질환 의심
AI도 똑같이 합니다. 수천, 수만 개의 데이터를 보며 패턴을 찾아냅니다.
스팸 메일 필터의 패턴 인식
AI가 스팸 메일에서 발견한 패턴:
- "당첨" + "무료" + "지금 클릭" = 스팸 확률 95%
- "회의" + "일정" + "참석" = 정상 메일 확률 90%
- "비밀번호" + "재설정" + "링크 클릭" = 피싱 확률 85%
처음 한두 개 메일로는 패턴을 못 찾습니다. 하지만 수만 개를 보면 명확한 규칙이 보이기 시작하죠.
얼굴 인식 알고리즘
스마트폰이 어떻게 여러분의 얼굴을 알아볼까요?
AI는 수천 장의 얼굴 사진에서 패턴을 학습합니다:
- 눈 두 개, 코 하나, 입 하나의 위치 관계
- 눈과 눈 사이의 거리
- 코의 모양
- 입의 크기와 위치
그리고 여러분 얼굴의 고유한 패턴을 기억합니다. 마치 지문처럼요.
놀라운 점은, AI가 조명이 바뀌거나 안경을 쓰거나 각도가 달라져도 여전히 여러분을 알아본다는 거예요. 왜냐하면 핵심 패턴을 배웠기 때문입니다.
예측은 어떻게 작동하는가?
과거로 미래 보기
예측의 핵심 원리는 간단합니다:
"과거에 이런 일이 있었으면, 미래에도 비슷할 것이다"

너무 단순한가요? 하지만 우리도 매일 이렇게 생각합니다.
교통 예측:
- 과거: 평일 아침 8시에는 항상 출근길이 막혔다
- 예측: 내일 아침 8시도 막힐 것이다
- 행동: 30분 일찍 출발하자
날씨 예측:
- 과거: 먹구름이 끼면 2시간 안에 비가 왔다
- 예측: 지금 먹구름이 끼니 곧 비가 올 것이다
- 행동: 우산을 챙기자
AI도 똑같습니다. 다만 훨씬 더 많은 데이터를 보고, 훨씬 더 복잡한 패턴을 고려할 뿐이죠.
Netflix는 어떻게 영화를 추천할까?
여러분이 지난 3개월 동안 본 영화를 생각해보세요:
- 액션 영화 15편
- 코미디 영화 8편
- 로맨스 영화 2편
Netflix AI는 이렇게 예측합니다: "이 사용자는 액션을 가장 좋아하고, 코미디도 좋아하고, 로맨스는 별로 안 좋아하는구나. 그럼 새로 나온 액션 영화를 추천해줘야겠다!"
그런데 여기서 더 똑똑한 점이 있어요. Netflix는 여러분과 비슷한 취향을 가진 다른 사람들이 뭘 봤는지도 확인합니다.
"이 사용자와 비슷한 사람들이 [영화 X]를 봤는데 평점이 높네? 그럼 이것도 추천!"
집값 예측 알고리즘
부동산 앱은 어떻게 집값을 예측할까요?
입력 데이터:
- 위치 (강남구, 서초구 등)
- 크기 (84㎡, 120㎡ 등)
- 층수
- 건물 연식
- 학군
- 지하철역까지 거리
AI가 발견한 패턴:
- 강남구 + 84㎡ + 10년 이하 + 역세권 = 평균 12억
- 노원구 + 84㎡ + 20년 + 역에서 멀다 = 평균 6억
수만 개의 거래 데이터를 학습해서 이런 패턴을 찾아낸 거예요.
그래서 새 집이 나오면 "위치, 크기, 연식을 보니 대략 9억 정도 될 것 같습니다"라고 예측할 수 있는 거죠.
예측은 100% 정확하지 않다
중요한 점이 있습니다.
예측은 추측이지, 확신이 아닙니다.
Netflix가 추천한 영화가 마음에 안 들 수도 있어요. 집값 예측이 실제 거래가와 다를 수도 있죠. 날씨 예보가 빗나갈 수도 있고요.
왜냐하면 세상은 복잡하고, 예측하지 못한 변수가 항상 있기 때문입니다.
하지만 데이터가 많을수록, 알고리즘이 좋을수록, 예측은 점점 정확해집니다.
의사결정 트리로 이해하기
가장 쉬운 AI 알고리즘
AI 알고리즘 중에서 가장 이해하기 쉬운 것은 의사결정 트리(Decision Tree)입니다.
왜냐하면 우리가 생각하는 방식과 똑같거든요!

병원 진료 과정
의사가 환자를 진단하는 과정을 나무 구조로 그려볼까요?
환자가 왔다
│
├─ 열이 있나?
│ ├─ 예 → 기침이 있나?
│ │ ├─ 예 → 목이 아픈가?
│ │ │ ├─ 예 → 감기 진단
│ │ │ └─ 아니오 → 독감 의심
│ │ └─ 아니오 → 다른 증상 확인
│ │
│ └─ 아니오 → 어디가 아픈가?
│ ├─ 배 → 소화기 문제 확인
│ └─ 머리 → 신경과 확인이게 바로 의사결정 트리입니다!
질문에 답하면서 결론으로 가는 나무 구조인 거죠.
영화 추천 의사결정 트리
Netflix가 영화를 추천하는 과정도 이렇게 그려볼 수 있어요:
사용자에게 영화 추천하기
│
├─ 액션을 좋아하나?
│ ├─ 예 → 최근 개봉작을 선호하나?
│ │ ├─ 예 → [신작 액션 영화] 추천
│ │ └─ 아니오 → [명작 액션 영화] 추천
│ │
│ └─ 아니오 → 코미디를 좋아하나?
│ ├─ 예 → [코미디 영화] 추천
│ └─ 아니오 → 로맨스를 좋아하나?
│ ├─ 예 → [로맨스 영화] 추천
│ └─ 아니오 → [다큐멘터리] 추천스팸 필터 의사결정 트리
이메일 스팸 필터는 이렇게 작동합니다:
새 이메일이 왔다
│
├─ "무료"라는 단어가 있나?
│ ├─ 예 → "클릭"이라는 단어도 있나?
│ │ ├─ 예 → 스팸 (확률 95%)
│ │ └─ 아니오 → 링크가 3개 이상인가?
│ │ ├─ 예 → 스팸 (확률 80%)
│ │ └─ 아니오 → 정상
│ │
│ └─ 아니오 → 발신자가 주소록에 있나?
│ ├─ 예 → 정상 (확률 99%)
│ └─ 아니오 → 첨부파일이 있나?
│ ├─ 예 → 의심 (확률 60%)
│ └─ 아니오 → 정상 (확률 90%)질문의 순서가 중요하다
의사결정 트리에서 중요한 건 질문의 순서입니다.
예를 들어, 스팸 필터에서:
- 먼저 "무료"를 확인하는 게 나을까요?
- 먼저 "발신자"를 확인하는 게 나을까요?
정답은: 가장 많은 정보를 주는 질문부터!
"발신자가 주소록에 있나?"를 먼저 물으면, 예/아니오로 크게 나눌 수 있습니다. 주소록에 있으면 거의 확실히 정상이니까요.
AI는 데이터를 보고 "어떤 질문이 가장 유용한가?"를 자동으로 찾아냅니다.
의사결정 트리의 장점과 단점
장점:
- ✅ 이해하기 쉽다
- ✅ 시각화할 수 있다
- ✅ 왜 그런 결정을 내렸는지 설명 가능
- ✅ 숫자가 아닌 데이터(색깔, 카테고리 등)도 처리 가능
단점:
- ❌ 너무 복잡해질 수 있다
- ❌ 데이터가 조금만 바뀌면 트리 전체가 바뀔 수 있다
- ❌ 직선으로 나눌 수 없는 패턴은 처리하기 어렵다
그래서 실제로는 수백, 수천 개의 트리를 함께 사용하기도 합니다. 이걸 "랜덤 포레스트(Random Forest)"라고 하는데, 나무가 모여 숲을 이루는 거죠!
균형이 중요하다: 과적합(Overfitting) vs 과소적합(Underfitting)
시험 공부의 비유
알고리즘 학습에서 가장 어려운 점은 균형입니다.

시험 공부를 생각해봅시다.
과적합(Overfitting) - 기출문제만 달달 외우기:
- 기출문제: 100점
- 실전 시험: 60점
왜일까요? 문제를 이해한 게 아니라 외웠기 때문입니다. 조금만 바뀌면 못 풀어요.
과소적합(Underfitting) - 너무 대충 공부하기:
- 기출문제: 50점
- 실전 시험: 45점
왜일까요? 기본 개념조차 제대로 못 배웠기 때문입니다.
적절한 균형 - 개념 이해 + 문제 연습:
- 기출문제: 85점
- 실전 시험: 80점
개념을 이해했으니 새로운 문제도 풀 수 있어요!
요리 학습의 비유
요리로도 설명할 수 있습니다.
과적합 - 엄마의 김치찌개만 똑같이 따라하기:
- 엄마 레시피: 완벽
- 다른 재료 사용: 실패
엄마가 쓰던 배추, 돼지고기, 양념을 똑같이 써야만 맛있어요. 다른 배추면? 망합니다. 응용이 안 돼요.
과소적합 - 요리의 기본도 모르는 상태:
- 엄마 레시피: 실패
- 다른 재료: 당연히 실패
불 조절도 모르고, 양념 비율도 모르니까요.
적절한 균형 - 원리를 이해하고 응용:
- 엄마 레시피: 맛있음
- 다른 재료: 응용해서 맛있게
"김치찌개는 돼지고기의 기름기와 김치의 신맛이 조화를 이뤄야 한다"는 원리를 알면, 다른 재료로도 맛있게 만들 수 있어요.
AI에서의 과적합
AI도 마찬가지입니다.
스팸 필터의 과적합: 학습 데이터: "무료 아이폰 당첨!" → 스팸 새 데이터: "무료 체험 이벤트" → 정상인데 스팸으로 분류
왜냐하면 "무료"라는 단어만 보고 판단하도록 너무 세밀하게 학습했거든요.
얼굴 인식의 과적합: 학습 데이터: 정면 사진만 새 데이터: 옆얼굴 사진 → 인식 실패
정면만 외워서, 다른 각도는 못 알아봐요.
AI에서의 과소적합
스팸 필터의 과소적합: 모든 메일을 "정상"이라고 판단
너무 단순하게 학습해서 스팸을 제대로 못 걸러냅니다.
집값 예측의 과소적합: "서울이면 10억, 지방이면 3억"
너무 대충 배워서 정확한 예측을 못 해요.
일반화(Generalization)가 목표
AI 학습의 목표는 일반화입니다.
일반화 = 본 적 없는 데이터에도 잘 작동하는 능력
학습 데이터에서 핵심 패턴을 배우되, 세세한 것까지 외우지 않는 거죠.
마치 "김치찌개를 만드는 원리"를 배워서, 어떤 재료를 써도 맛있게 만들 수 있는 것처럼요.
실전에서 균형 잡기
그렇다면 AI 개발자들은 어떻게 균형을 잡을까요?
1. 데이터를 나눈다:
- 학습 데이터 (70%): 이걸로 배워요
- 검증 데이터 (15%): 이걸로 과적합 체크
- 테스트 데이터 (15%): 최종 성능 평가
2. 복잡도를 조절한다:
- 의사결정 트리를 너무 깊게 만들지 않기
- 질문을 너무 많이 하지 않기
- 적절한 선에서 멈추기
3. 정규화(Regularization):
- 너무 복잡해지면 페널티 주기
- 단순하게 만들도록 유도
이건 마치 선생님이 "요점 정리를 하라"고 하는 것과 같아요. 모든 걸 다 외우지 말고, 핵심만 정리하라는 거죠.
알고리즘, AI의 심장
오늘 우리는 AI의 심장이라 할 수 있는 알고리즘에 대해 배웠습니다.
오늘 배운 핵심 내용
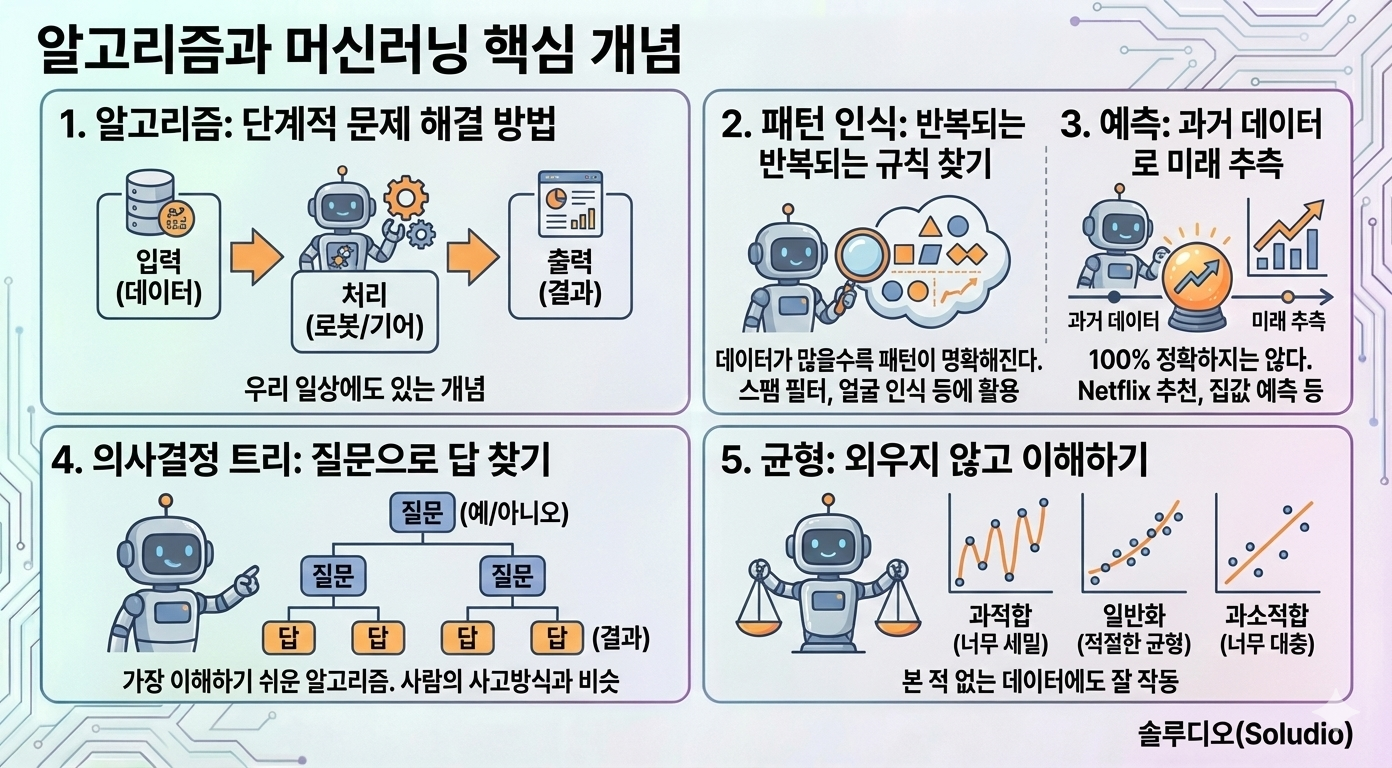
✅ 알고리즘 = 단계적 문제 해결 방법
- 입력 → 처리 → 출력
- 우리 일상에도 있는 개념
✅ 패턴 인식 = 반복되는 규칙 찾기
- 데이터가 많을수록 패턴이 명확해진다
- 스팸 필터, 얼굴 인식 등에 활용
✅ 예측 = 과거 데이터로 미래 추측
- 100% 정확하지는 않다
- Netflix 추천, 집값 예측 등
✅ 의사결정 트리 = 질문으로 답 찾기
- 가장 이해하기 쉬운 알고리즘
- 사람의 사고방식과 비슷
✅ 균형 = 외우지 않고 이해하기
- 과적합: 너무 세밀하게 학습
- 과소적합: 너무 대충 학습
- 일반화: 본 적 없는 데이터에도 잘 작동
알고리즘의 진짜 의미
알고리즘이 왜 중요할까요?

알고리즘은 AI가 생각하는 방법이기 때문입니다.
사람의 뇌가 전기 신호로 생각한다면, AI는 알고리즘으로 생각합니다. 알고리즘이 없으면 AI는 그냥 데이터 더미일 뿐이에요.
좋은 요리사는 좋은 레시피를 가지고 있듯이, 좋은 AI는 좋은 알고리즘을 가지고 있습니다.
그리고 가장 중요한 점:
AI는 데이터에서 최적의 알고리즘을 스스로 학습합니다.
우리가 일일이 규칙을 정해주지 않아도, AI는 수천, 수만 개의 데이터를 보면서 "아, 이렇게 하면 되는구나!"를 깨달아요.
이게 바로 머신러닝의 핵심이고, AI가 강력한 이유입니다.
다음 이야기
알고리즘의 개념을 이해했으니, 이제 더 깊이 들어갈 차례입니다.
다음 글에서는 인공 신경망에 대해 알아보겠습니다.
"신경망"이라는 이름에서 알 수 있듯이, 이건 사람의 뇌를 모방한 AI입니다. 우리 뇌의 뉴런이 어떻게 작동하는지, 그걸 어떻게 컴퓨터로 구현했는지, 재미있는 이야기가 펼쳐질 거예요.
'AI' 카테고리의 다른 글
| 구글 Antigravity(안티그래비티): 코딩의 중력을 거스르다! (개요, 특징, 설치법) (0) | 2025.11.27 |
|---|---|
| [AI 개념 정리 5] 딥러닝이란? '딥'한 이유와 CNN, RNN 쉽게 이해하기 (0) | 2025.11.26 |
| [AI 개념 정리 4] 인공 신경망(Neural Network)이란? 회사 조직 구조, 채용 결정 예시를 통해 AI 쉽게 이해하기(뉴런, 신경망) (1) | 2025.11.25 |
| [AI 개념 정리 2] AI는 어떻게 공부할까? 넷플릭스와 알파고로 배우는 머신러닝 원리 (0) | 2025.11.23 |
| [AI 개념 정리 1] AI 종류 완벽 정리: 약한 AI와 강한 AI 차이점은? (feat. ChatGPT) (2) | 2025.11.23 |



